

We're thrilled to announce EdgeDB 3.0, a release that comes loaded with new features and improvements. The truly exciting part? The entire feature set is inspired by our users. From enthusiastic individual developers pouring passion into their weekend apps to post-Series B companies making big bets on EdgeDB, this version is shaped to their needs, aiming to deliver the best developer experience in databases.
Wondering what our users have been saying about EdgeDB, your one and only graph-relational database? Join our 1,800+ members Discord to find out! However, if we were to cherry-pick a few highlights, they’d include appreciation for the overall database efficiency and streamlined experience, the high-level strict data model with type mixins and polymorphism, built-in schema migrations, composability and expressiveness of our query language, EdgeQL, our robust TypeScript query builder, and our unwavering commitment to being 100% open source—all on the rock-solid foundation of PostgreSQL. Our job was clear cut: weave together the positive feedback, constructive criticism, and calls for enhancements from our users, and channel it all into EdgeDB 3.0. 🖤
Gearing up to draft this blog post, it was pretty darn evident that covering all of the new features without turning it into a novel would be quite a feat. So, prep your oxygen tanks! This post is a deep dive. And to ensure we don’t lose you on a wild goose chase for that elusive, tiny scrollbar, let’s have a quick rundown of the topics we’ll tackle in this post:
-
We’ve given our schema declaration language syntax a sleek new makeover, replacing
->with:and makingpropertyandlinkkeywords optional. -
Triggers and mutation rewrites let you implement advanced validation and make the database react to your queries in interesting ways.
-
EdgeDB’s graphical UI has been…transformed, adding a new Web REPL, a visual query builder, and a new client settings interface.
-
Get under the hood of your EdgeQL queries with the new
analyzecommand. -
The new
edgedb watchcommand makes schema migrations get out of your way when rapidly iterating. -
EdgeQL gets splats, nested modules, new set operators, and more.
-
There’s
ext::pgvector. Should we even explain this one? -
EdgeDB now supports SQL in read-only mode. We want EdgeDB to play nice with your existing business intelligence and analytics toolset.
-
Our native Java and Elixir drivers are ready to go. Or should we say, our native “Kotlin, Scala, Clojure, Java, and Elixir” drivers?
-
EdgeDB 🌤️ Cloud is in private beta and we can’t wait for you to try it out.
Before we delve deeper, let’s make a quick but essential announcement. It’s been nearly a year since the launch of EdgeDB 2.0, and we believe now is the perfect time to adopt a faster and more predictable release rhythm. From now on, look forward to a fresh major version of EdgeDB every 4 months 🗓️. For those who prefer to upgrade less frequently, every third release will wear the badge of an LTS (Long Term Support) version, offering at least 12 months of support. In line with this, EdgeDB 3.0, being the third release, proudly steps up as an LTS. Let’s get rolling!
Just stumbled upon EdgeDB and have an
irresistible urge to learn more about it right this very moment?
Click here.
EdgeDB is a new database with its own query language, type system, and set of tools and conventions. Let’s go through a few selling points to give you a taste:
A declarative schema
…which lets you express computed properties, inheritance, functions, complex constraints and indexes, and access control rules.
type User {
required email: str {
constraint exclusive;
}
}
type BlogPost {
required title: str;
required published: bool {
default := false
};
author: User;
index on (.title);
}A builtin migration system
…consisting of a database-native migration planner, automatic migration history tracking, and a CLI-based workflow.
$
edgedb migration createCreated dbschema/migrations/00001.edgeql
$
edgedb migrateApplied dbschema/migrations/00001.edgeql
A modern, lean query language
…that matches the expressive power of SQL while remaining more composable
and less verbose (and eliminating JOIN!)
select BlogPost {
title,
trimmed_title := str_trim(.title),
author: {
email
}
}
filter not .publishedA TypeScript query builder
…that can express arbitrary EdgeQL queries and automatically infer the query return type.
e.select(e.BlogPost, post => ({
title: true,
trimmed_title: e.str_trim(post.title),
author: {
email: true
},
filter: e.op("not", post.published)
}))And it’s 100% open source, has great performance, and is powered by Postgres under the hood.
There’s a lot more to EdgeDB, and we have some great learning materials: you can play with the interactive in-browser tutorial, look through our documentation, or read our book! But before you do that, let’s get back to discussing the new features of EdgeDB 3.0. 🧐
Streamlined SDL
EdgeDB’s Schema Declaration Language (SDL) is painstakingly crafted to be expressive and powerful, but we’ll admit—it could be sharper, more succinct, and more in tune with the popular programming languages. As we aim to eventually allow defining ad-hoc types directly in your queries, it became clear that the syntax needed a bit of a cleanup.
A picture is worth a thousand words, so here are the new and the old syntaxes:
abstract type Content {
required title: str;
multi actors: Person {
character_name: str;
};
}abstract type Content {
required property title -> str;
multi link actors: Person {
property character_name -> str;
};
}In short, -> is replaced with the familiar : while link and
property keywords become optional in most contexts. As we are committed to
maintaining backwards compatibility, the old syntax will be supported forever.
If you’re curious about the future direction of our type system (or perhaps
you’re wondering why we ever thought using -> was a good idea),
feel free to dig into RFC 1022!
Triggers and mutation rewrites
Triggers have been among the most requested features since the launch of EdgeDB 1.0. However, we needed time to build the infrastructure to implement the design we had envisioned. You see, traditional triggers in relational databases are usually implemented as procedures and have non-trivial calling overhead. On top of that they are opaque to the database query planner preventing optimization of the entire query operation. Finally, they don’t have full access to the actual data specified in the query, being limited to observing only the database’s before and after states.
In EdgeDB 2.0, we introduced access policies, a feature that works by inlining access control expressions specified in the user’s schema right into incoming EdgeQL queries. This enabled more flexibility than PostgreSQL’s row-level security, and laid the groundwork for new features and future optimizations. With our compiler’s new inlining infrastructure and a penchant for not taking the easy route, we started working on triggers. We ended up rethinking the conventional approach and designed a solution that we believe is more flexible and easier to reason about. The result? EdgeQL got two new mechanisms: “Triggers” and “Mutation Rewrites”. A couple examples are in order:
type Person {
required name: str;
trigger log_update after update for each do (
insert AuditLog {
action := 'update',
target_name := __new__.name,
change := __old__.name ++ '->' ++ __new__.name
}
);
}
type AuditLog {
action: str;
timestamp: datetime {
default := datetime_current();
}
target_name: str;
change: str;
}type Post {
required title: str;
required body: str;
author: str;
title_modified: datetime {
# Only update `title_modified` if a new value
# for `title` was specified in the query:
rewrite update using (
datetime_of_statement()
if __specified__.title
else __old__.title_modified
)
}
}type Post {
required title: str;
required body: str;
author: str;
byline: str {
# Cache computed byline on every update.
rewrite insert, update using (
'by ' ++
__subject__.author ++
' on ' ++
to_str(__subject__.created, 'Mon DD, YYYY')
)
}
}abstract type WithModifiedTime {
# A reusable abstract type -- just inherit
# from it any type that needs an `mtime`.
mtime: datetime {
rewrite update using (
# Allow mutations to specify a custom `mtime`,
# or compute it if none was provided.
datetime_of_statement()
if not __specified__.mtime
else .mtime
)
}
}In essence, the distinction between the two is quite straightforward:
a Trigger cannot alter the object that activated it, but it can do pretty
much anything else. A Mutation Rewrite, on the other hand, enables you to
intercept mutating queries and rewrite them conditionally based on the old or
new value, or even on what was specified precisely in the mutating query.
To put it in SQL terms, EdgeDB’s mutation rewrites correspond to
SQL’s before triggers, while EdgeDB’s triggers align with SQL’s
after triggers.
Watch this video for a few more examples:
Both Triggers and Mutation Rewrites pack a punch when combined with abstract types and the ability to derive your types from multiple other types, constructing your schemas like Lego. We can’t wait to see how you’ll mix and match these tools to craft reusable schemas and push the boundaries of what’s possible with EdgeDB!
Revamped UI
When we shipped EdgeDB 2.0 with its integrated graphical user interface, we were convinced we had nailed it. It was functional, beautiful, and made visualizing and navigating through complex schemas a breeze. It featured a dedicated data entry panel, negating the need for a separate admin panel in early-stage projects, and offered a built-in IDE-like editor to write and run EdgeQL queries.
However, as time passed and feedback trickled in, it became apparent that some aspects needed polishing, and others warranted an entire redesign. Our EdgeQL editing experience fell into the latter category. The 2.0 UI attempted to merge two distinct modes of interaction into one UI: a REPL-like experience for rapid query prototyping and an IDE-like editor. It soon became clear that these two modes were not a two-for-one deal and needed separate attention. Back to the drawing board!
With EdgeDB 3.0, we’ve tackled the shortcomings of the 2.0 UI by introducing several distinct query editing experiences:
-
The new Web REPL feels like having a real terminal in your browser, only better. Like its terminal counterpart, it supports various
\commands, but with a twist—the output is interactive. For a touch of nostalgia, you can tune in to a classic 90s FM station and run the\retrocommand. 🥂 -
The new Editor panel is a full-fledged lab for prototyping and debugging complex EdgeQL queries (more on that in the next section!) It keeps track of all your queries in a new History panel, so you can quickly revisit that version of your query that definitely worked.
-
The Editor panel also features a built-in visual query designer, perfect for those late hours when you can barely hold your mouse. Jokes aside, it is quite convenient for quick data exploration and prototyping.
The bottom line is, our graphical UI just got significantly better. It’s always
ready for you, without the need to hunt for another DB GUI app or run Electron
apps. Just enter the $ edgedb ui command, and you’re all set.
Query analysis
Query analysis is essential in declarative languages like SQL or EdgeQL, where the outcome of the computation, not the process, is the focus. Users do not control the specific mechanisms the database uses to execute their query, however this is where query analysis can help:
-
It offers insights into how the database interprets your queries, ensuring they perform as intended.
-
It allows studying the execution plan, which includes index usage, sorting operations, and more. By analyzing the plan you can spot potential performance bottlenecks and optimize your query or schema accordingly.
Although EdgeDB is built on PostgreSQL, directly exposing the underlying EXPLAIN
command wouldn’t work. It is powerful for sure, but has a steep learning
curve. Plus, EdgeQL’s composable nature can lead to multiple complex operations
within a single query, translating into long, elaborate SQL. PostgreSQL can chew
through that just fine, but for non-DBAs, explaining that SQL would be
overwhelming. So we needed to design our own mechanism (powered by EXPLAIN
under the hood) with an accessible and user-friendly output.
The result is the new analyze command in EdgeQL. Drop the keyword in front
of your EdgeQL query and run it in REPL or in the web UI to receive a clear and
concise visualization of the query plan, directly mapped to your query.
This intuitive tool allows you to get details about the execution process
without drowning in complexity.
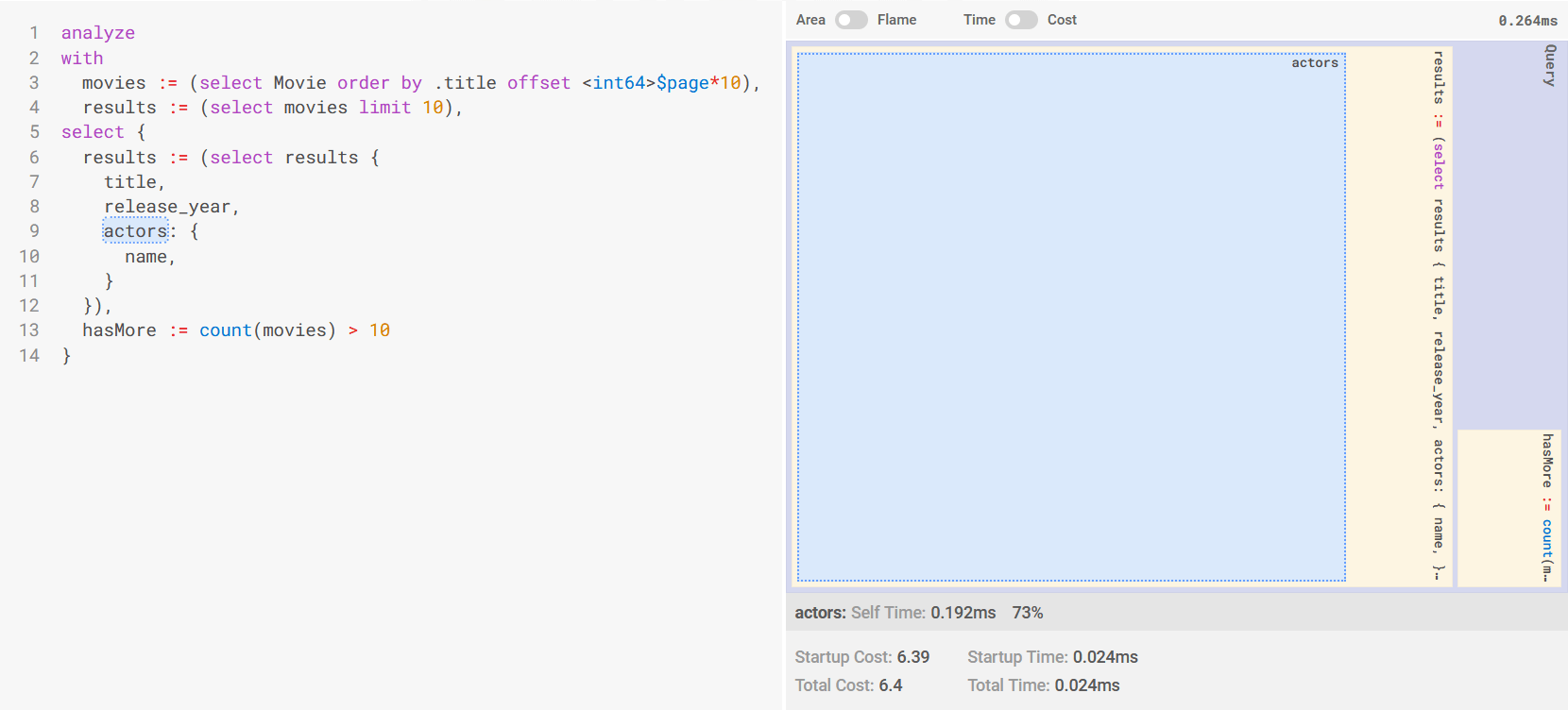
The analyze keyword was selected purposefully (instead of re-using the
conventional SQL’s EXPLAIN keyword) for its future potential.
Beyond just queries, we plan to use this new command for analyzing schema
migrations and…types. For instance, knowing the count of objects of
a specific type and understanding their storage requirements is crucial for
maintaining a healthy database. The analyze type command could provide
instant access to such statistics, becoming an invaluable tool in your
database management workflow.
We plan to rapidly iterate on the analyze command’s implementation,
design, and the depth of information it returns. As usual, we rely on your
feedback to identify areas for enhancements. Please share your thoughts
with us in our Discord or GitHub.
We’re always excited to hear from you!
edgedb watch
Having a strict schema has its perks. For instance, it allows you to maintain data consistency, lets the database engine run queries efficiently knowing all about the data layout and types, and even lets you reflect your schema into your programming language, be it TypeScript, Python, or others, creating a convenient API. But let’s face it, wrestling with schema can also be a real pain. That’s why EdgeDB comes with built-in tooling to help you manage the entire migration process. And with EdgeDB 3.0, we’re adding a new tool to the kit: the “watch” mode.
The new edgedb watch command is designed to act as an assistant to you.
Running in the background while you iterate on your schema, it automatically
applies all your schema edits to the development database, freeing you from
the need to run migration commands manually. And when you’ve made all the
necessary changes to the schema, run edgedb migration create to generate
a proper migration.
Evolving EdgeQL
While adding the new analyze command and triggers/rewrites, we continued
to also evolve the EdgeQL syntax and the Standard Library. Here are some of
the most noteworthy additions:
-
You can now nest a module inside another module, repeating the process until your schema sparks joy! ✨ On a more serious note, nested modules enable us to expand the Standard Library with new modules without risking backwards compatibility.
-
UUIDs can now be directly cast to objects. If the ID doesn’t exist, or if it’s of the wrong type, the system will generate an error:
Copydb>
select <Hero><uuid>'01d9cc22-b776-11ed-8bef-73f84c7e91e7';{default::Hero {id: 01d9cc22-b776-11ed-8bef-73f84c7e91e7}} -
The new
intersectandexceptset operators will help your inner John Venn go wild. For example:Copydb> ... ... ... ... ... ... ... ... ...
with big_cities := ( select City filter .population > 1_000_000 ), s_cities := ( select City filter .name like 'S%' ) select (big_cities intersect s_cities) { name };{ default::City {name: 'San Antonio'}, default::City {name: 'San Diego'} } -
The new
assert()function allows for custom descriptive errors from queries, functions, or triggers.
One of the biggest syntactic additions to EdgeQL are the “splats”. The closest
prior art to it is the SQL’s SELECT *, and now you can do the same thing in
EdgeQL too:
select Movie {*};This query would list all Movie objects with all of their properties.
However, you often want to see even deeper into your data when using the REPL.
For this we have a double-splat:
select Movie {**};This query would list all Movie objects including their top-level
links, along with their properties. But wait, there’s more! You can use splats
on type expressions, as in:
select Hero {
(Hero & Villain).**
}and for expressing polymorphic queries:
select Person {
[is Hero].**
}Read the docs to learn more about splats! And if you want to see have a feel of the design space we had to explore, check out the splats RFC!
ext::pgvector
With the launch of EdgeDB 3.0, we’re also introducing the integration of ChatGPT into our documentation. Just click on the “Ask GPT” button within the Docs and ask your question. 😮 We look forward to your feedback to help us understand how supportive it is!
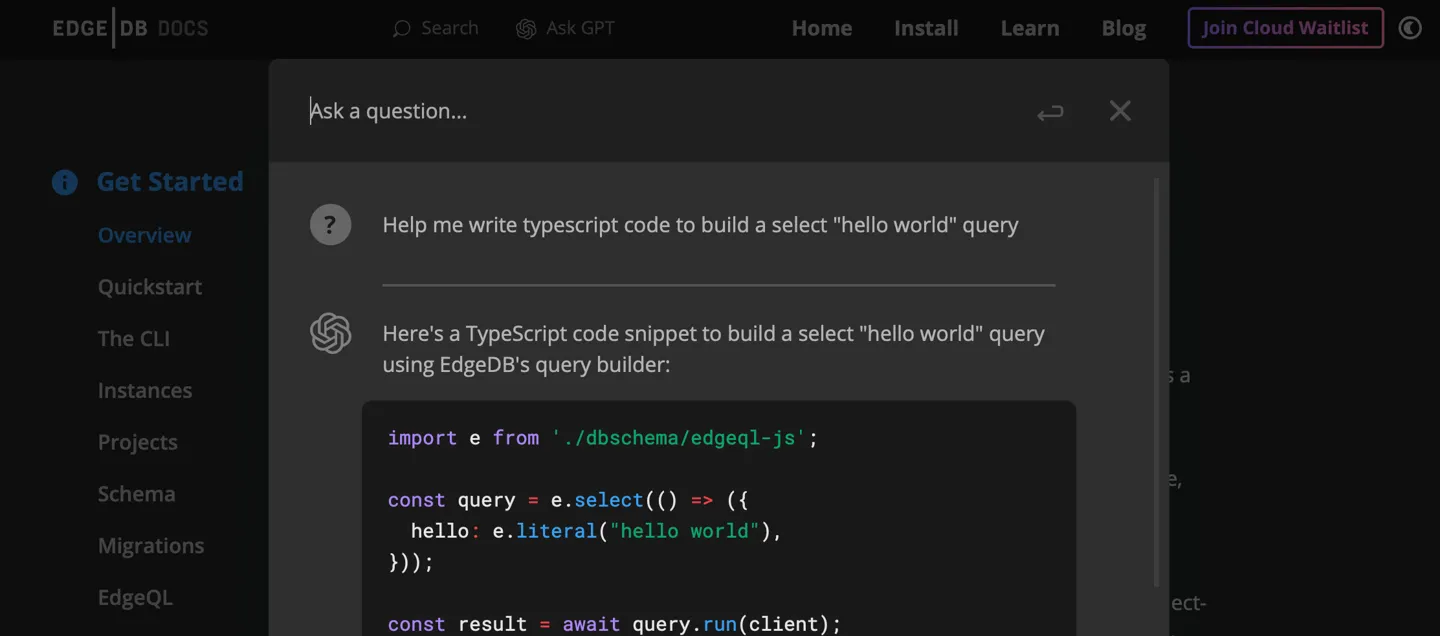
Asking ChatGPT for assistance with the TypeScript query builder.
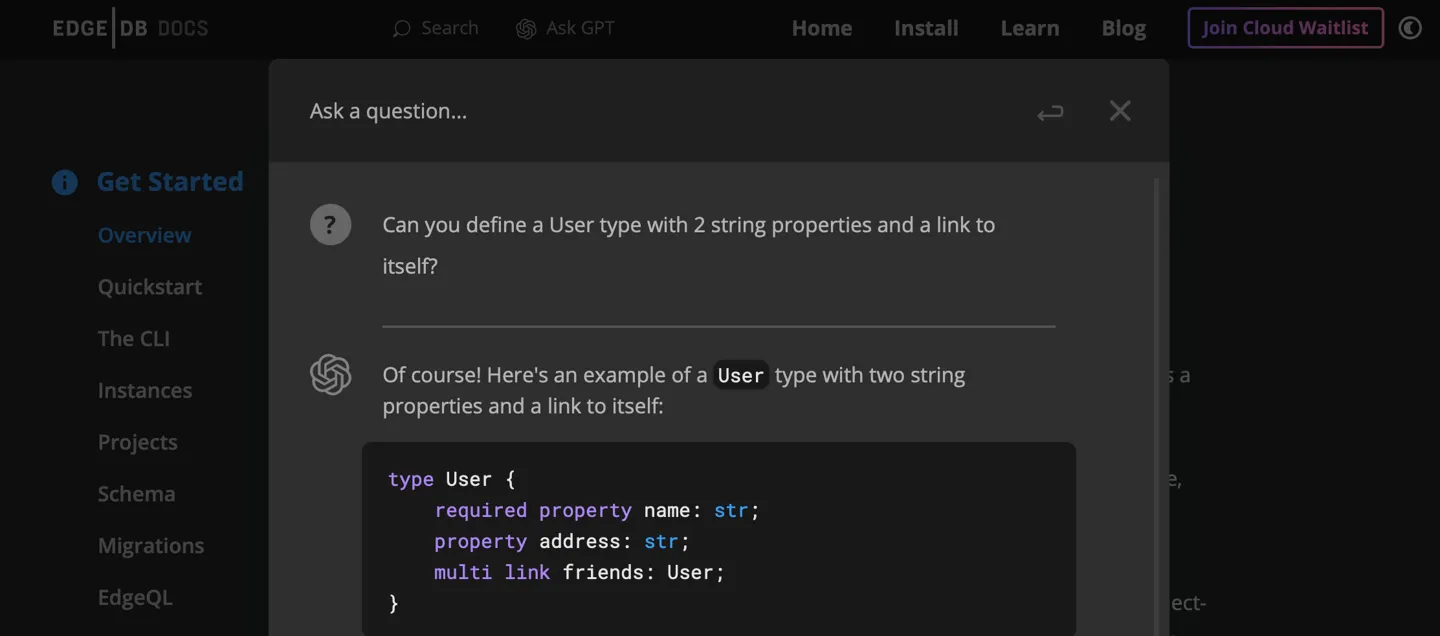
Asking ChatGPT for guidance in writing a schema.
Naturally, all interactivity on our site is powered by EdgeDB.
To support this feature, we needed an efficient way to store and query
embeddings. That’s where the popular PostgreSQL pgvector extension comes
in handy. It’s now packaged and distributed together with EdgeDB, and
is available as the ext::pgvector extension.
Using the extension is quite straightforward and self-explanatory:
using extension pgvector;
module default {
scalar type GPTEmbedding extending
ext::pgvector::vector<1536>;
type Document {
required content: str;
embedding: GPTEmbedding;
index ext::pgvector::ivfflat_cosine(lists := 100)
on (.embedding);
}
}with
vec as module ext::pgvector,
target := <GPTEmbedding>$target_embedding,
threshold := <float64>$threshold
select Document {
*,
dist := vec::cosine_distance(target, .embedding)
}
filter .dist < threshold
order by .dist empty last
limit 5BI and analytics
Since SQL had a bit of a head start on us, there’s an industry of business intelligence and analytics products that were designed specifically to work with it. While our users love EdgeDB, they also want the ability to generate reports and dashboards using tools such as Metabase, Cluvio, Airbyte, and others. We plan to work with some of these tools to eventually add native EdgeQL support. But in the meantime, we’re providing our users with a way to access their data using SQL, in addition to EdgeQL and GraphQL. We approached this task with meticulous attention to detail, striving to create a high-quality reflection of our data model back to a pure relational one. Watch this quick clip below to see how it works!
The implementation details are rather intriguing and merit a mention:
-
To support SQL we had to implement a “SQL to SQL” compiler. While EdgeDB envelops PostgreSQL at its core and compiles the graph-relational model to a properly normalized relational form, the underlying relational schema is optimized for machines, not humans.
-
EdgeDB exposes multiple protocols through a single network port. You can connect to EdgeDB with an HTTP client to use GraphQL or access its built-in Prometheus metrics endpoint. Alternatively, you can connect one of our client libraries to use the binary protocol directly or channel it via HTTP. And with 3.0, you can connect to EdgeDB with your PostgreSQL client library or a tool like
psql. The server is intelligent enough to figure out what you’re connecting with and provide what you need. -
The SQL protocol benefits from the same built-in connection pooling that native EdgeDB clients enjoy.
Java & Elixir
Our goal is to have first-class EdgeDB clients for all mainstream programming languages and runtimes. As of now, EdgeDB supports TypeScript & JavaScript, Python, Go, .NET, Dart, Deno, and Rust. Today we’re announcing the addition of Java (which covers the plethora of JVM-based languages like Kotlin, Scala, Clojure, and others) and Elixir to this lineup. Let’s see them in action with a few simple examples:
import com.edgedb.driver.EdgeDBClient;
void main() {
var client = new EdgeDBClient();
client.query(String.class, "SELECT 'Hello, Java!'")
.thenAccept(System.out::println);
}import com.edgedb.driver.EdgeDBClient;
import reactor.core.publisher.Mono;
void main() {
var client = new EdgeDBClient();
Mono.fromFuture(
client.querySingle(
String.class, "SELECT 'Hello, Java!'")
)
.doOnNext(System.out::println)
.block();
}fun main() {
val client = EdgeDBClient();
runBlocking {
client.query(
Long::class.java, "SELECT len('Hello, Kotlin!')"
)
.thenAccept(System.out::println)
.await()
}
}@main
def main(): Unit = {
val client = EdgeDBClient()
client.query(classOf[Long], "SELECT len('Hello, Scala!')")
.asScala
.map(System.out.println)
}iex(1)>
{:ok, client} = EdgeDB.start_link()iex(2)>
arg = [16, 13, 2, 42]iex(3)> ...(3)> ...(3)>
^arg = EdgeDB.query_required_single!(
client, "select <array<int64>>$arg", arg: arg
)[16, 13, 2, 42]
As is the standard with EdgeDB client libraries, the new Java and Elixir bindings:
-
Take full advantage of our network protocol (aggressively caching data encoding/decoding pipelines) and implement native support for all of the built-in datatypes.
-
Ensure zero-config connectivity that automatically resolves the configuration for EdgeDB projects.
-
Incorporate automatic client-side connection pooling, session tracking, and recovery for network and transaction serialization errors.
Feel free to explore the documentation for our new Java client and Elixir client for more information.
Cloud
And…there’s one more thing! EdgeDB Cloud is now available in closed beta!
We are designing our cloud product to have just as good DX as EdgeDB itself:
-
Seamless integration with our client libraries and tools.
-
Minimal configuration required, making setup a breeze.
-
Exceptionally user-friendly UI, designed with intuitive navigation and ease of use in mind.
The ultimate goal is to make EdgeDB Cloud a natural extension of your existing toolchain, amplifying your productivity without the need to reinvent your workflows.
To participate in the beta please join our Discord
and post to the #cloud channel, or click this button:
Wrapping up
EdgeDB 3.0 shaped up to be an exceptional release. I couldn’t be more proud of our exceptional team and we’re all incredibly excited about what the future holds.
EdgeDB is a labor of love and passion for us. We invite you to join our mission to build a database that truly empowers developers. There’s no better time to start building with EdgeDB than right now.
Thank you for your support and enthusiasm! ❤️



