

Please try our chatbot tutorial to build a documentation chatbot of your own!
Searching developer documentation can be fickle. If you don’t know exactly how to phrase your query, you might not find the information you’re looking for, even if it’s right there waiting to be found. Chatting with a human makes it more likely you’ll be understood, but it doesn’t scale. Fortunately, the rise of the large language models has enabled a new mode of getting answers to your questions: chatting with documentation. You can now chat with the EdgeDB documentation via a feature we call “Ask AI.”

Clicking the “Ask AI” button will open the UI allowing you to ask questions:
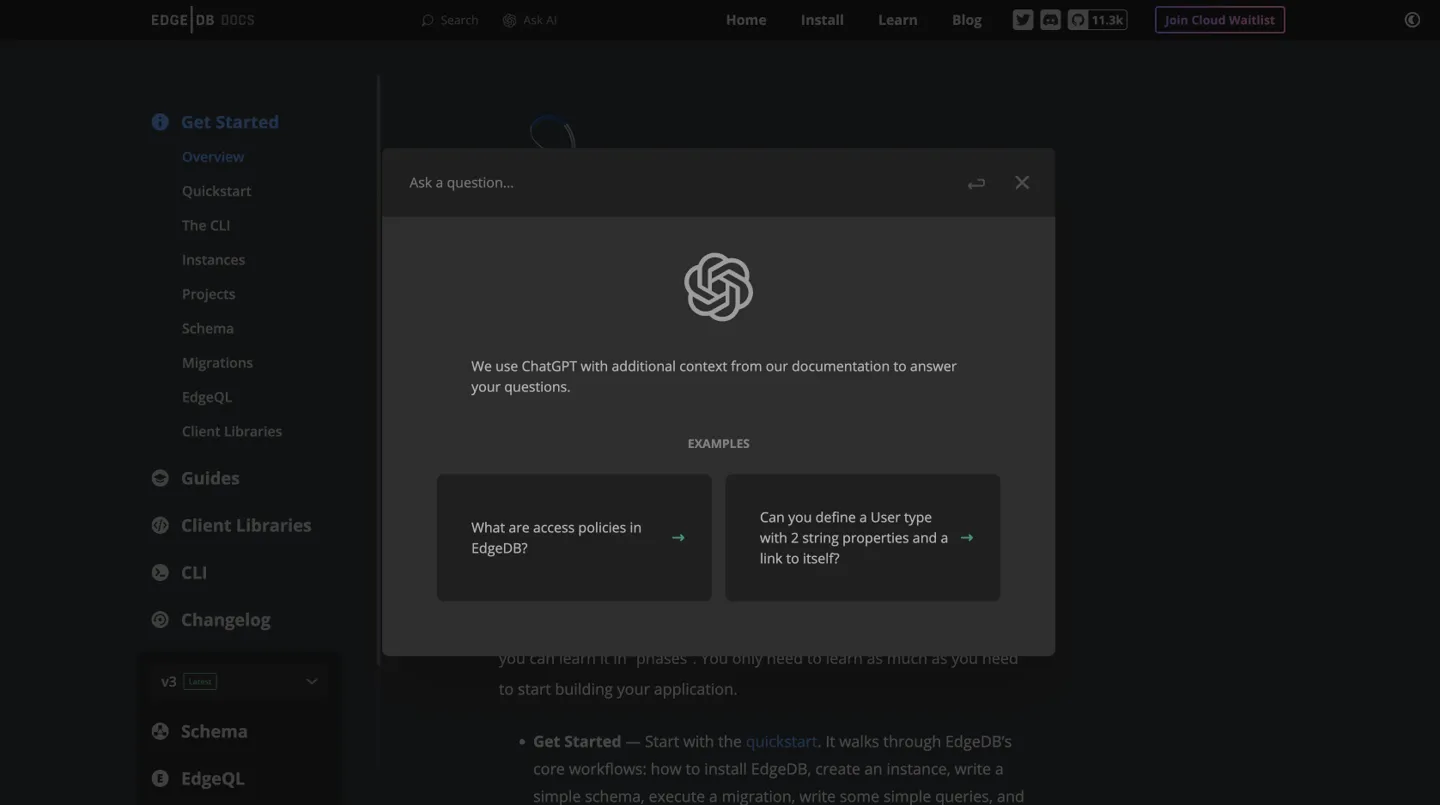
The Ask AI interface, ready for your questions!
Ask AI is backed by OpenAI’s ChatGPT. It is an advanced language model that uses machine learning algorithms to generate human-like responses based on the input it’s given. Trained on a diverse range of internet text, it’s capable of answering questions, writing essays, summarizing long documents, translating languages, and even simulating conversations, among other tasks. It has become very popular among businesses as a support chatbot. You feed it your documentation and company data and… voila: it is ready to replace your support workforce!
🤨 Umm, well… not quite — it’s not always correct, and it still can’t understand as much context as a human can — but it can help get users on the right track more quickly than the alternatives for many queries.
In this blog post, I’ll walk you through why we decided to add Ask AI to our website, a high-level overview of steps we took, a common problem we couldn’t avoid, and some future ideas we have to improve it.
Why bother implementing ChatGPT in the first place?
As EdgeDB grows, our documentation is growing too. We understand it may be hard for an EdgeDB newbie to find exactly what they’re looking for. That’s why we invite users to join our Discord where we can guide those who can’t find what they need in the documentation.
Even though Discord is an awesome tool, it has its downsides. We wanted to test what we could do to make it even easier and faster to get the help you need to keep building. We think that Ask AI and our Discord community complement each other quite nicely, and having both of them is much more powerful than having either one alone.
Discord strengths
-
Real-time Human Interaction: Humans understand humans better than ChatGPT ever will. We just get each other, and that can’t be replicated easily.
-
Building Rapport/Empathy: When people communicate with others, rapport is the natural by-product. You get to know us and EdgeDB better. We get to know you, which helps us understand what you need and ultimately makes EdgeDB a better database.
-
Community-driven Support: Discord communities can lead to peer-to-peer support, where community members help each other solve issues based on their own experiences.
-
Multi-format Support: Discord allows for text, voice, and video communication, providing more avenues for users to seek support.
ChatGPT strengths
-
Automated Responses: ChatGPT can provide instant, automated responses to queries, which is useful for providing support 24/7 and getting you answers to your questions faster.
-
Scalability: AI like ChatGPT can handle an unlimited number of queries simultaneously, making it useful for businesses or communities with a large number of users.
Discord isn’t going anywhere, so keep using that and our documentation alongside Ask AI. Some questions require human reasoning or more context than Ask AI can handle. In those cases head to Discord and let us and the community know how we can help. For simple, straightforward questions though, using the documentation and Ask AI should provide you with answers quickly so you don’t lose your momentum.
How we made it happen
This is a quick overview. We’ll have a full guide available soon!
Fine-tuning vs embeddings
There are two ways to integrate ChatGPT and language models in general: through fine-tuning or via embeddings. GPT models have hundreds of millions to billions of parameters, and fine-tuning them requires access to powerful hardware. Fine-tuning GPT models also needs a large amount of high-quality, task-specific data, which is often not available or may require significant resources to generate.
Embeddings, on the other hand, provide a simpler, more resource-efficient way to leverage machine learning for natural language processing (NLP) tasks. They have become a common approach for use-cases like ours. Embeddings are a way to convert words, phrases, or other types of data into a numerical form that a computer can do math with. In the context of NLP, word embeddings are used to transform words into vectors, where the position of each word is determined by its semantic and syntactic properties. These vectors allow machine learning models to perceive semantic relationships between words: for instance, synonyms are closer to each other, and words that often appear in similar contexts are grouped together.
pgvector support
Since we went with embeddings, we will have to store them somewhere. But, wait a second… EdgeDB can’t do that! Well, it couldn’t do that. 😉
To solve this problem, we added support for pgvector in EdgeDB 3.0.
pgvector is a PostgreSQL extension for vector similarity search, which can
also be used for storing embeddings. We’ll look at an example of usage a bit
later, but before we can store embeddings, we need to have some embeddings to
store!
Generating embeddings
Generating embeddings consists of three steps:
-
Converting our documentation into a unified format that is easily digestible by the OpenAI API. After a survey of other similar efforts, I found Markdown is the most straightforward format to feed to OpenAI, so I decided to use it too.
-
Splitting the converted documentation into sections that can fit into the GPT context window. All OpenAI models currently have token limits, which means that the data we submit to the specific APIs — along with the data we get back — has to fit within the model’s limit. A rough estimate for OpenAI’s language models is that one token equals 3/4 of a word or approximately four characters (for English text). There is no “perfect size” for the section, the general advice is that it should not be too small or too big, but big enough to contain and explain some semantics. We ended up with sections between 60 and 1,500 tokens, with the majority being between 100 and 800.
-
Creating embeddings for each section using OpenAI’s embeddings API. Read OpenAI’s embeddings API documentation to learn more about it.
Once the embeddings are generated, it’s time to store the vector data in an EdgeDB database.
How to store embeddings in EdgeDB
Before storing any data in the database, we have to create a schema. Below you
can see the schema we use for storing embeddings (i.e., the embedding
property of the Section type, which uses the custom scalar type
OpenAIEmbedding), along with their relevant documentation sections (i.e.,
the content property of the Section type).
using extension pgvector;
module default {
scalar type OpenAIEmbedding extending
ext::pgvector::vector<1536>;
type Section {
required path: str {
constraint exclusive;
}
required content: str;
required checksum: str;
required tokens: int16;
required embedding: OpenAIEmbedding;
}
index ext::pgvector::ivfflat_cosine(lists := 3)
on (.embedding);
}pgvector is implemented as an EdgeDB extension, so in order to use it in
your schema you have to activate the ext::pgvector module with using
extension pgvector at the beginning of the schema file. This module gives you
access to ext::pgvector::vector as well as few similarity functions and
indexes you can use later to retrieve embeddings. Read our pgvector
documentation for more details on the extension.
With the extension active, you may now add vector properties when defining your type. However, in order to be able to use indexes, the vectors in question need to be a of a fixed length. This can be achieved by creating a custom scalar extending the vector and specifying the desired length. OpenAI embeddings have length of 1,536, so that’s what we use in our schema.
Here’s what a random embedding looks like straight from OpenAI:
[
0.01889467,
0.007864347,
0.0030647821,
-0.045942817,
-0.017926084,
...
]After we get all of the embedding vectors from OpenAI, we need to store them. The TypeScript binding offers several options for writing queries. We recommend using our query builder, and that’s what you’ll see in use here. For reference I’ll also show those same queries in EdgeQL. I use this query to bulk insert all of the section data and embeddings generated by OpenAI:
with
sections := json_array_unpack(<json>$sections)
for section in sections union (
insert Section {
path := <str>section['path'],
content:= <str>section['content'],
checksum:= <str>section['checksum'],
tokens:= <int16>section['tokens'],
embedding:= <OpenAIEmbedding>section['embedding'],
}
)const query = e.params({sections: e.json}, ({sections}) => {
return e.for(e.json_array_unpack(sections), (section) => {
return e.insert(e.Section, {
path: e.cast(e.str, section.path),
content: e.cast(e.str, section.content),
checksum: e.cast(e.str, section.checksum),
tokens: e.cast(e.int16, section.tokens),
embedding: e.cast(e.OpenAIEmbedding, section.embedding),
});
});
});
await query.run(client, {sections});Let’s generate answers
Now that we have embeddings ready, we can answer users’ queries. When someone submits a question:
-
We query the EdgeDB database for the documentation sections most relevant to the question using a similarity function. A similarity function measures how closely related two vectors are. This is often used in NLP to find how similar two words, phrases, or documents are to each other based on their embeddings. We are using the
cosine_distancesimilarity function, but there are a few other options. (Learn about them in the pgvector documentation.)EdgeQLTS query builderCopywith target := <OpenAIEmbedding>$embedding, matchThreshold := <float64>$matchThreshold, matchCount := <int16>$matchCount, minContentLength := <int16>$minContentLength select Section { content, tokens, dist := ext::pgvector::cosine_distance(.embedding, target) } filter len(.content) > minContentLength and .dist < matchThreshold order by .dist empty last limit matchCountCopyconst matchThreshold = 0.3; const matchCount = 10; const minContentLength = 20; const query = e.params( { target: e.OpenAIEmbedding, matchThreshold: e.float64, matchCount: e.int16, minContentLength: e.int16, }, (params) => { return e.select(e.Section, (section) => { const dist = e.ext.pgvector.cosine_distance( section.embedding, params.target ); return { content: true, tokens: true, dist, filter: e.op( e.op(e.len(section.content), ">", params.minContentLength), "and", e.op(dist, "<", params.matchThreshold) ), order_by: { expression: dist, empty: e.EMPTY_LAST, }, limit: params.matchCount, }; }); } ); const sections = await query.run(client, { target: embedding, matchThreshold, matchCount, minContentLength, });In the code above we use a few variables:
-
embedding: The embedding vector retrieved from OpenAI for the user’s question. -
matchThreshold: The similarity threshold. Only matches with a similarity score below this threshold will be returned. You can try different values here between 0 and 2 and see how answers change in the next step. When using cosine distance, a distance of 0 means that the vectors are pointing in the same direction.
-
matchCount: How many sections we want to get from the database. Getting too many doesn’t make sense because we can only include a few of them as context in the next step. -
minContentLength: Ignore sections shorter than this. (In our case we don’t really need this since we already know our sections have more than 20 characters).
-
-
Inject these relevant sections as context into the prompt, together with the user question, and submit a request to OpenAI. OpenAI will give us back an answer that relies on its previous general knowledge and on the context we sent to it, with greater focus on the context. This is also where we tell ChatGPT how to behave and what tone to have (e.g., a funny or serious tone).
-
Stream the OpenAI response back to the user in realtime.
What can Ask AI do for you?
You can ask straightforward questions:
-
What is a link property?
-
What are globals?
-
What are access policies and how do I use them?
Or you can ask it to help with your specific case, defining your schema in SDL based on a description for example. For very long and complex schemas, it may not be able to give you 100% correct or full answers due to limited context size and high complexity of reasoning which are still beyond ChatGPT’s capabilities.
It’s a cool tool that will help you move faster, and it will free us up to build even better resources for you to be more successful with EdgeDB… but it’s not without its flaws.
How we handle AI “hallucinations”
If you’ve played around with a language model before, you know their responses are not perfect. One of the biggest complaints about ChatGPT is that it can come up with wrong answers and present them very confidently. When we finished our first implementation of Ask AI and started testing it, we confirmed that our integration is not immune to this flaw. We tried to minimize these with a very explicit system message telling ChatGPT to only answer if it’s very confident in the answer and if it finds the answer in our documentation. In other cases, we instructed it to answer with: “Sorry, I don’t know how to help with that.”
Even with this additional instruction, incorrect answers are still possible, so we decided to build a mechanism for users to report them, while continuing to search for more ways to minimize them. If you’ve tried Ask AI, you may have noticed in the UI that we provide vote up (👍) and down (👎) buttons for each answer. We keep track of voting events along with questions and answers connected to those events in order to continue improving the quality of results. (Note that we do not keep track of any identifying user data — only the question, the answer, and the vote.)
By tracking bad answers, we can investigate whether the problem is in our documentation — maybe some sections of the documentation are not clear enough or are missing important info — and we can work on improving it which will in turn improve your Ask AI experience.
What’s next?
We’re currently working on implementing chat history into Ask AI. This will allow you to navigate through your previous queries and chats. We’re improving the UI, and we are updating our documentation every day so that Ask AI can provide you better answers.
The models and technology that back Ask AI are also becoming better every day. With these improvements happening from every possible angle, Ask AI will be one tool in our toolbox as we continue to build the world’s most developer friendly database. And by using what you’ve learned here and in our chatbot tutorial, we’re giving you the tools to make your project better for your users too!


